Rapid Internal Adoption of Claude Code
The Anthropic team is intensively testing Claude Code internally. Over the past 52 days, the Claude team has launched more than 50 significant feature updates. Reports indicate that 80% of Anthropic employees use Claude Code daily, with high-frequency users incurring bills in the six-figure range; one employee’s monthly usage reached $150,000.
Simultaneously, external usage of Claude is also accelerating noticeably.
“Several friends working at large tech companies and startups tell me they spend over $1,000 daily on Claude Code or Codex tokens, equivalent to $365,000 annually,” remarked Hyperbolic co-founder Yuchen Jin. “We are not far from the era where enterprise spending on large model tokens exceeds human employee costs.”
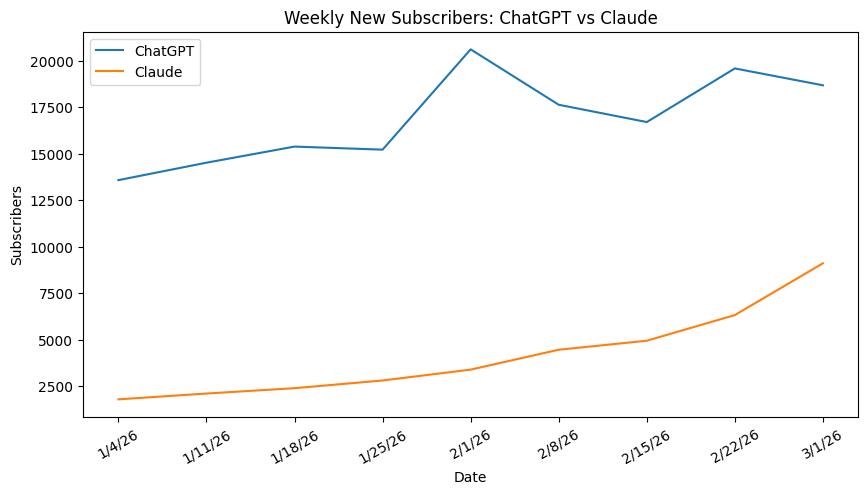
Consumer transaction analysis company Indagari analyzed data from approximately 28 million American consumers and billions of anonymous credit card transactions. The results show that the number of paid subscribers for Claude is growing at an unprecedented rate, doubling this year, which an Anthropic spokesperson confirmed.
Most new subscribers are opting for the basic Pro plan, priced at $20 per month, while higher-tier plans cost $100 and $200 per month.
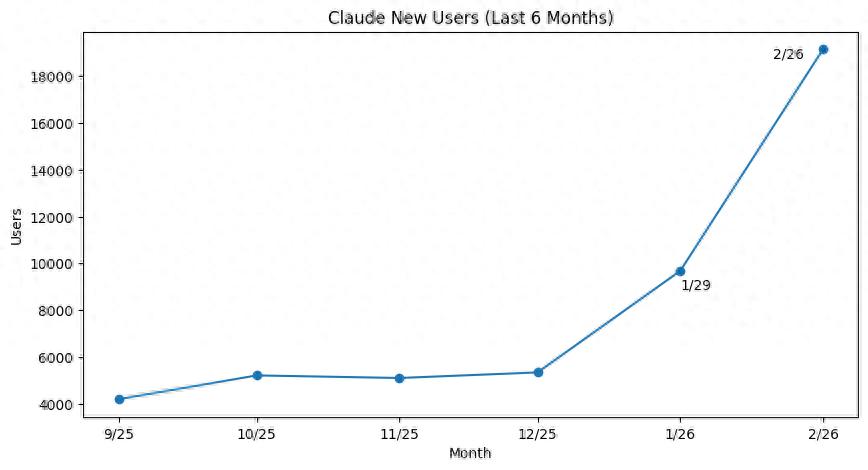
Whether through Anthropic’s Super Bowl ads mocking ChatGPT or its conflicts with the U.S. Department of Defense, or the recent launch of Claude Cowork and the new Computer Use feature, these factors have contributed to significant growth.
Despite this, there remains a considerable gap between Claude and ChatGPT. Data shows that OpenAI continues to attract new paid subscribers rapidly, maintaining its status as the largest player in the consumer AI platform market.
User Limitations and Risks
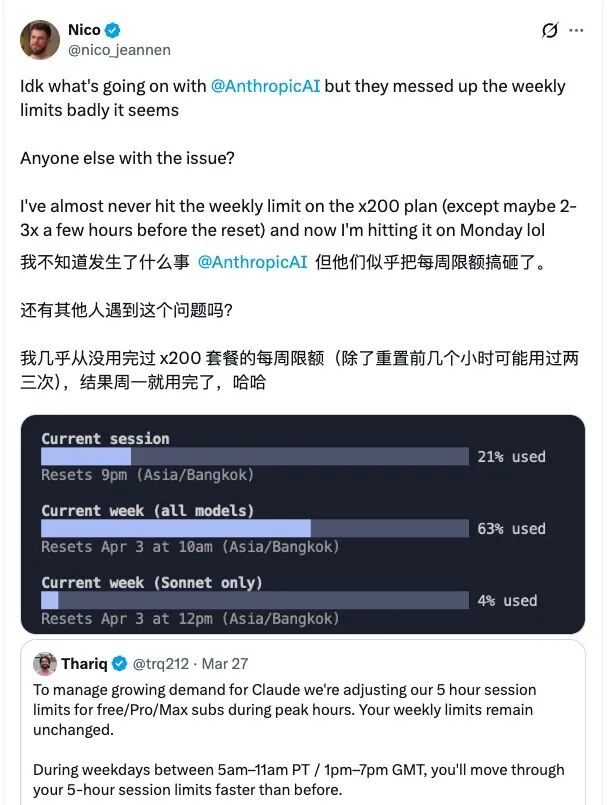
As the user base expands, Anthropic recently adjusted its previously opaque usage limits for Claude: during peak demand periods, it reduced the service intensity provided to users to balance the growing demand with its service capacity.
Anthropic technical team member Thariq Shihipar stated on social media, “To address the increasing demand for Claude, we are adjusting the 5-hour session limit for free, Pro, and Max subscribers during peak hours. Your total weekly limit remains unchanged.”

This means that during peak hours from 5:00 AM to 11:00 AM Pacific Time, Claude users may exhaust their allotted usage for a 5-hour session in less than 5 hours. Conversely, the same 5-hour session during other times allows users to accomplish more work. The reason for this flexible definition is that Anthropic has not disclosed how many tokens are allowed within the 5-hour session window.
According to Shihipar, “About 7% of users will encounter session limits they previously would not have faced, especially Pro tier users. If you are running high token consumption tasks in the background, moving them to non-peak hours will help extend your session limits.”
Anthropic stated that during other lower-demand periods, the company has increased available capacity, so overall, users’ total usage limits have not net lost. Shihipar explained, “The overall weekly limit remains unchanged; it’s just the distribution of those limits throughout the week that has changed.”
After this adjustment was announced, users quickly reported changes in their actual experiences. On March 30, a user subscribed to the highest x200 plan noted that they had rarely reached their weekly limit before, but by Monday of that week, they had already exhausted their entire quota.
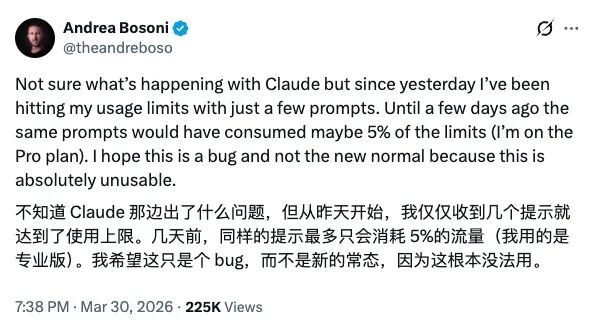
A Pro user reported that starting March 29, they hit the usage limit after sending just a few prompts, whereas a few days prior, the same actions would have consumed only about 5% of their quota.
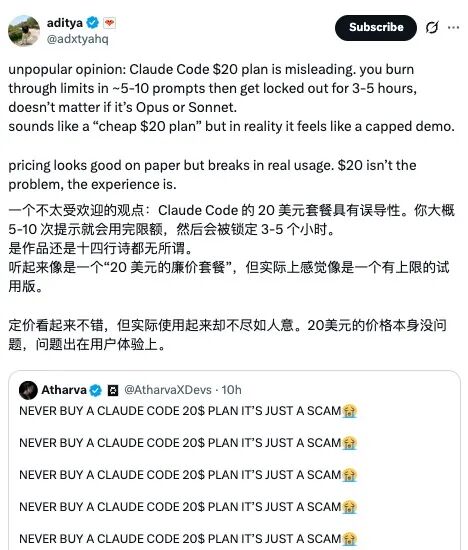
On the Opus 4.6 model, performance significantly declines after token consumption exceeds approximately 20%, causing the model to become unstable and nearly unusable. The claimed capability of supporting 1M context seems to fail in practical experience; in contrast, the 0% to 15% usage range is the most stable and effective.
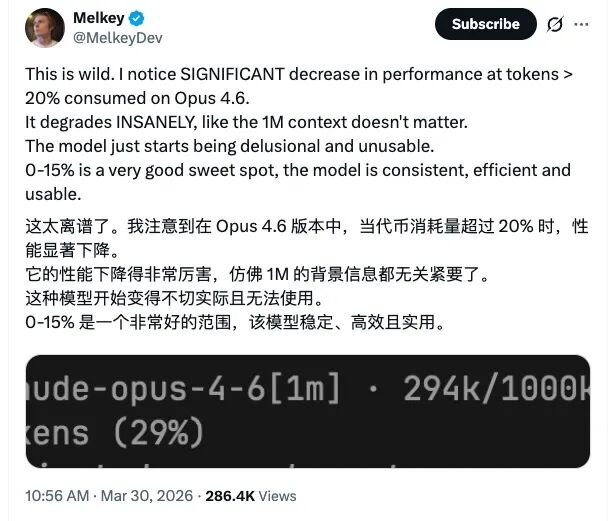
These feedbacks are not isolated cases but are concentrated among high-frequency users who engage in long contexts and parallel tasks, representing the current highest cost and usage segment for Claude. This also implies that those who first feel the tightening of limits are not occasional light users but rather advanced users who have deeply integrated Claude into their daily development processes.
On March 29, a heavy user reported that after a year of intensive use of Claude, their account was suddenly banned by the platform.
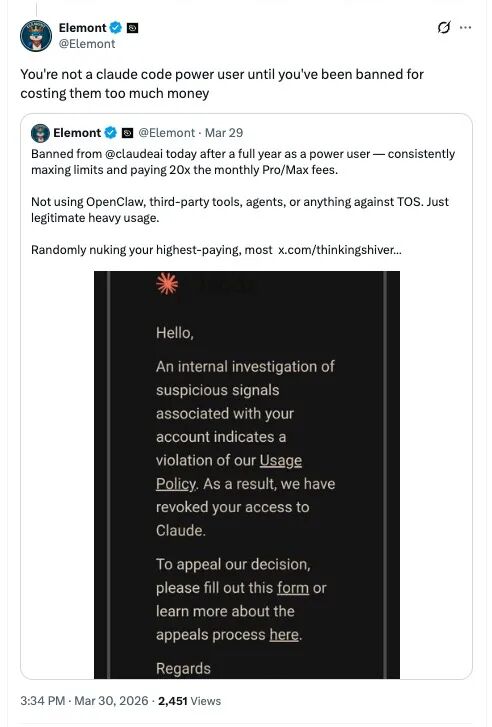
They claimed that they had consistently maxed out their usage limits over the past year, with costs reaching 20 times the Pro/Max monthly fee; meanwhile, they had not used OpenClaw, third-party tools, Agent, or any methods that violated service terms, merely engaging in legitimate heavy usage.
In their view, the platform’s “randomly banning” the highest-paying, most loyal users is not only extremely unfriendly to customers but also a terrible business decision. “How do you expect to retain users this way? Or is your goal to clear out those who consume the most computing power?” they questioned, demanding a more transparent explanation from Anthropic.
They sarcastically added, “If you haven’t been banned for being too costly, you aren’t a true Claude Code power user yet.”
In response, Anthropic officials quickly addressed the situation. On March 31, Anthropic spokesperson Lydia Hallie stated that the team had noticed “users are hitting usage limits far faster than expected” and are actively investigating this as a top priority issue.
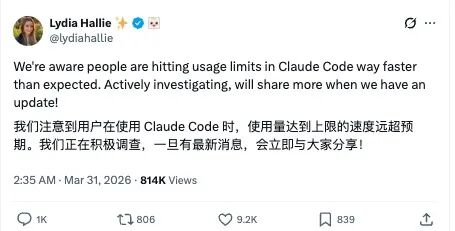
Thus, while the official emphasis is on “total limits remaining unchanged,” in actual usage, some users, especially high-frequency ones, have seen their effective limits substantially compressed during this phase.
Moreover, users have reported abnormal API consumption as well.

Currently, Anthropic sells its AI services in two forms: one is API, and the other is subscription service.
- API users pay according to public pricing, with billing items including various types of token usage: Base Input Tokens, 5m Cache Writes, 1h Cache Writes, Cache Hits & Refreshes, and Output Tokens.
- Subscription users, including Free, Pro ($20 per month), Max 5x ($100 per month), and Max 20x ($200 per month), operate under a set of undisclosed usage limit constraints. Anthropic has not clearly stated how these limits are calculated, leaving users unable to plan their token usage in advance.
Anthropic explains in its documentation: “Your usage will be affected by various factors, including the length and complexity of the conversation, the features you use, and the Claude model you choose during chats. Different subscription plans (Pro, Max, Team, etc.) correspond to different usage limits, with paid plans typically offering higher caps.”
Claude users can view their consumption progress within a dashboard for their 5-hour daily session limit and weekly usage limit. If users exceed their limits, Claude will lock them out unless they are willing to pay extra for additional usage.
Under this new token allocation mechanism, developers can expect to accomplish more work during non-peak hours, while less work will be completed during other times. However, how many Californians will wake up at 5 AM to code intensely? This undoubtedly raises concerns among many developers.
Meanwhile, users must bear the potential engineering risks that Claude Code may suddenly unleash.
Claude Code has recently been reported to have a high-risk defect: under certain exceptional circumstances, the background refresh mechanism of the plugin market may mistakenly execute git reset --hard origin/main on the user’s current project repository, triggering every 10 minutes and clearing uncommitted local changes.
Under normal circumstances, the program periodically updates the official plugin market copy located at ~/.claude/plugins/marketplaces/claude-plugins-official/; however, when this directory is corrupted, especially when the .git directory is missing, the related Git operations may not execute in the plugin market directory but mistakenly affect the user’s current project repository. The submitter stated that behavioral analysis of the compiled binary shows that this process executes git fetch origin and git reset --hard origin/main.
The danger is that such issues are not easily detected at first. When all user changes have been committed, reset --hard appears not to cause obvious consequences, making the problem manifest as an “occasional failure”; however, once users are in a normal development state with uncommitted changes, they may face repeated data loss.
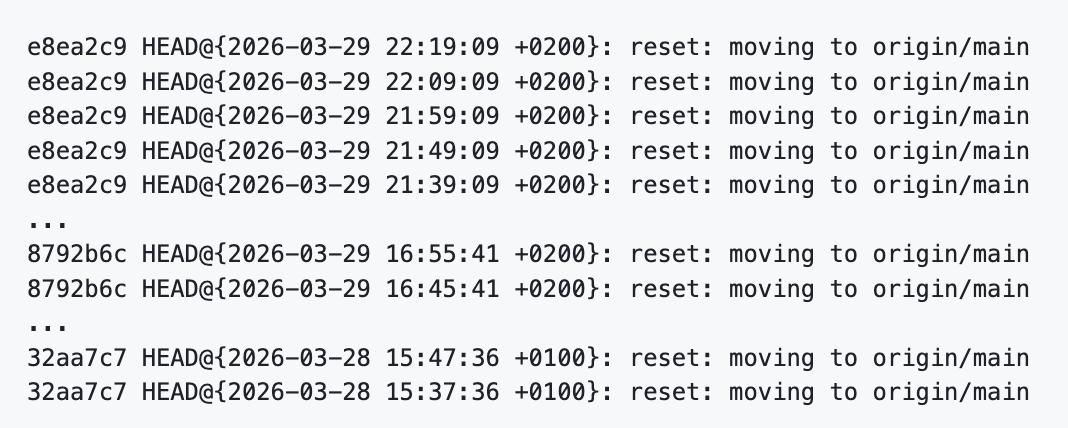
This is not an isolated experience but has been reported multiple times by developers. “I’ve encountered this several times. Once, it even pushed directly to GitHub; for personal private projects, GitHub does not enable branch protection,” developer jeswin stated.
In fact, issues related to this product, now composed of 100% AI code, have been continuously submitted on GitHub. Just in March, Claude’s servers experienced at least five outages.
AI tool users find themselves in this contradictory situation: they are paying heavily for AI products while also bearing the potential engineering risks of those products.
The Decline of Free AI
Initially, many companies attracted a large user base through “high subsidies,” “near-free offerings,” or even “unlimited trials.” However, this strategy is now retracting, and free AI may genuinely be coming to an end.
The first to send clear signals was Google.
In the past, Google was extremely aggressive on the road of free and subsidized offerings. They believed that as long as they made products “good enough and cheap enough,” they could lure a large number of users away from OpenAI and Anthropic, reclaiming the AI traffic entrance for themselves.
However, this strategy comes at a high cost. A significant amount of GPU resources is occupied by nearly non-paying users, squeezing resources that should serve high-value customers, ultimately affecting the experience of paying users. For instance, users reported that when purchasing computing power at API prices in T3 Chat, they encountered situations where Gemini 3.1 could not respond due to overload; even monthly subscribers paying $250 could not use it properly when Gemini 3.1 Pro was first launched, with the official explanation being insufficient capacity, fundamentally due to excessive free resources.
This tension has begun to reflect in product strategies. Gemini CLI has initiated a new round of adjustments: more strictly identifying violations, prioritizing certain types of accounts for traffic, and limiting free-tier users’ access to the Gemini Pro model. Meanwhile, GitHub Copilot for students has also changed, no longer supporting the free selection of some high-end models originally included.
“There is now no reason to continue using Antigravity or Gemini CLI,” one user stated bluntly. “Google’s subsidies have significantly shrunk, even completely excluding free users from Gemini Pro. While I somewhat like Gemini Flash, it is completely inadequate for daily development work. Using the free version of Gemini 3 Flash or Gemini CLI for serious development feels like using a toy keyboard to develop real applications, recording an album with a toy karaoke machine; it is simply not on the same level and seems absurd.”
Even more outrageous is the official statement regarding “quota control”: if you want direct control over quotas and billing, please use the paid API key for AI Studio or Vertex.ai. In other words, the Gemini CLI is directly telling users, “We will reduce the available quota within your paid subscription; if you want to use more, you must buy an API key separately.” This approach is extremely aggressive and clearly drives users away.
The fundamental reason for Google’s contraction of free benefits is that this model itself is becoming increasingly difficult to sustain.
There is no such thing as “free computing power” in the world. If a company is willing to give away AI inference for free, it certainly has ulterior motives: it might profit from advertising, convert potential customers through trials, or collect data on a large scale. The more realistic situation is a combination of factors that barely allows the free model to exist commercially; this cost must be compensated from elsewhere.
Continuing to provide large-scale free subsidies no longer makes sense. Although the cost of individual tokens for cutting-edge large models continues to decline, models like 4o and 4o mini are now ten times cheaper than the early GPT-4 32K, the reality is that the complexity and scale of inference demand are rising even faster.
Compared to 2023, the number of tokens generated per question has increased at least tenfold. The reason is simple: today’s models no longer just answer isolated questions; they incorporate the entire codebase into context, call tools, execute multi-step operations, gather external data, and generate new content at each step. The significant increase in token generation naturally leads to higher costs. More importantly, the cost increase associated with the same prompt has already offset or even exceeded the benefits brought by the decrease in single token prices.
In the past, a single message might generate only 200 tokens; now it could generate 200,000 tokens, drastically increasing GPU usage time. As long as a GPU is serving one user, it means it cannot serve others at the same time, which itself incurs high costs.
Longer generated content, higher GPU usage, and longer processing times continue to rise. This is why many AI tools have been unable to establish truly reasonable billing models.
Initially, most users did not understand the abstract billing unit of tokens, so many products chose more intuitive methods: charging by the number of messages. Many developer tools and chat products had adopted this path.
However, the problem quickly became apparent: not every message costs the same.
For example, in a chat tool, sending a message like “What is 2 plus 2?” might only take 11 tokens for the model to answer; however, asking the model to write several poems about React could instantly multiply the generated tokens by dozens. In reality, the token consumption difference for a single message can reach up to 400 times. The lowest requests might only be worth $0.001, while the highest could burn several dollars.
If a company prices its product at $8 per month, but certain users incur API costs of $1 per prompt, that means a single request consumes one-eighth of the entire subscription revenue. Such a product will inevitably incur losses as soon as user activity increases slightly.
This is why, over the past year or two, the debate over whether AI tools should charge by message count or actual usage has intensified. Last year, when Cursor switched from charging by message count to usage-based billing, user emotions exploded, essentially because this contradiction was finally brought to light: a message is no longer just “a message” but represents an entire cost system behind it.
Advertising and Data Cannot Support the Free Model
Many believe that companies like Google, which originated from advertising, are naturally more suited to offer free AI. After all, advertising revenue is so high; why not use some of it to subsidize inference? However, according to broadcaster Theo-t3․gg, the reality is far from simple.
The advertising business seems to generate “billions annually” because it is built on a massive scale of exposure, yet the money earned per individual display is actually quite small. Even in channels with a high-quality developer audience and relatively high CPM, the revenue per individual view is often just a tiny fraction.
He directly states from his experience, “Advertising hardly makes money on an individual level.” For instance, in 28 days, his videos accumulated 20,000 days of watch time but only earned $9,000 in ad revenue (Google’s estimated share after deductions was about $18,000), resulting in an ad revenue of only about $0.28 per view, far from covering the potential AI inference cost of over $1; he can continue only because of sponsorships.
Another frequently cited reason for explaining free strategies is data. This is not entirely wrong; the industry has repeatedly proven that high-quality feedback from real chat history is highly valuable for training new models.
You cannot use data generated by a weaker model to create a new model that thoroughly surpasses the original model, but you can get close, and at a much lower cost than training from scratch. For this reason, many companies are particularly concerned about the flow of prompts, context, and usage feedback. There have been various rumors that someone is attempting to intercept input and output data through intermediary services to train their models. Even if these matters cannot be publicly verified, the logic behind them is consistent: real user data itself is one of the most important assets in the AI era.
Cursor-type products can also benefit from user data, but it is far from sufficient to support completely free services. Although data is valuable, it is not valuable enough to allow a company to survive solely on “giving away inference for data.”
The core reason why major companies implement free and subsidized offerings is to capture users.
A company can lure you away from your original product in two ways: either it is clearly better, or it is “good enough and cheaper.” In today’s rapidly changing AI tool landscape, users are increasingly finding it difficult to determine “who is clearly better,” especially when everyone already has several subscriptions costing $20, $100, or even $200 per month. In this context, price becomes the easiest competitive advantage to convey.
However, a frequently overlooked detail in the free model is that not all free users are the same.
The ideal free user is someone who says, “If it’s free, I’m willing to try; if it’s really better, I’m willing to pay.” But there is another type of user who only appears when the product is free and disappears as soon as it charges. This type of user is a disaster for the company. They consume a lot of GPU, customer service, time, and support costs but will never become paying customers. Often, their consumption on the support side is even higher than that of high-value users.
Free or low prices can attract a large number of potential users, but if the product itself is not excellent, users cannot be retained, and the initial subsidy investment will be entirely wasted. The free strategy can attract many users to try, but truly quality conversion comes from the user group that pays due to free experience and excellent products. GitHub is a typical case: users start using it for free, and when they enter the workforce, they drive enterprise payments, forming a healthy commercial loop.
However, if the product is not good enough, the free strategy will only attract low-value users who only use the product when it is free, which is a death line. These users will only consume GPU, electricity, human resources, and customer service costs, with almost zero probability of paying, and their service costs are often higher.
Google has precisely fallen into this predicament. Its product competitiveness is insufficient, relying solely on free leads, resulting in a highly polarized user base for Antigravity: on one end are novice programmers lacking payment capabilities, while on the other end are senior users unwilling to pay, including well-known developers like Linus Torvalds also taking advantage of free quotas. After attracting a large number of users who consume resources without generating revenue, Google ultimately had to tighten this subsidy model that should not have existed long-term.
Why Anthropic Can Navigate This?
Despite both offering subsidies, OpenAI and Anthropic have taken entirely different paths.
OpenAI now resembles a growth-stage company “seizing territory.” It has not yet gained a sufficiently high market share, so it is willing to adopt more aggressive subsidies, temporarily increase Codex rate limits, and promote more external tool integrations to ensure its models appear in more developers’ workflows.
For OpenAI, the most important thing at this stage is to become “the best option” rather than “the only option.” This is why it appears more open and willing to cooperate with ecosystem partners than Anthropic. However, this openness is more a commercial choice during the growth phase and not necessarily a long-term stance. Once the market landscape continues to change, it may not shift back.
Anthropic’s subsidy logic only holds under one premise: it must turn users into lifelong customers. If developers can freely switch between Cursor, Codex CLI, or other multi-model tools, the high subsidies offered by Anthropic will struggle to yield long-term returns.
A developer with strong payment capability may incur several thousand dollars in inference costs monthly, but they often bring this tool into their team or even their entire company. This means that many people, while subscribed to the service, use only a small portion of their quotas, effectively subsidizing the real heavy users.
For example, Theo-t3․gg mentioned that while he retains a $200 monthly subscription, he has recently been primarily using Cursor and Codex CLI, resulting in low actual usage of Cloud Code, indirectly subsidizing other users.
Enterprise procurement further amplifies this effect: when an engineering organization subscribes uniformly, the actual high-frequency users often constitute only a minority. Assuming the entire team has activated the service, ultimately only about 20% of people will use it normally, and those who use it intensively may only account for 10%. This means that the vast majority of subscription fees come from those who do not fully utilize their quotas, which is key to the feasibility of high-priced plans.
Theo-t3․gg noted that Anthropic’s $200 monthly subscription could correspond to up to $5,000 worth of computing resources. In the short term, the platform indeed loses money on heavy users; however, as inference costs continue to decline and many users do not fully utilize their quotas, the platform has a chance to gradually balance the books and even move towards profitability. More importantly, these high-value individual users will also bring team and enterprise-level diffusion, further enhancing their lifetime commercial value.
In contrast, free users do not possess this logic. If a group of users only appears when the product is free and disappears once it charges, they cannot form long-term returns and will consume a lot of GPU, support resources, and operational costs. Google has precisely made a mistake in this regard.
Moreover, Google’s issue is not just excessive subsidy but more like an organization that has lost control. It indeed desperately wants to acquire real AI customers, but internally, too many teams are competing for GPU and resources without communication, and the developer tools team cannot even convince the company to open certain models to their products because resource priorities have already been given to free users.
In a sense, Google’s subsidies are not the result of a “thoughtful choice” but rather a situation where they “subsidized themselves into a pit.”
Conclusion
For developers using these AI tools, we are currently in a contradictory yet brief window period.
On one hand, competition among large companies keeps subsidies and subscription services very generous; on the other hand, everyone is beginning to realize that this state will not last forever. Free offerings will decrease, subsidy levels will become more precise, model choices will be increasingly controlled by platforms, and those truly high-value plans will become scarcer resources.
Therefore, for users, this may be a “golden period” for using these tools: you can still obtain far more value than your payment cost at relatively low prices. Whether it’s $20 or $200 per month, as long as you can truly utilize these tools, the productivity gains they bring remain highly cost-effective.
However, for small companies, this is also the most challenging time for competition. Large companies are using subsidies to grab customers while compressing the space for newcomers, and small companies not only have to bear the original API costs but also face a market mindset where users are educated to believe that “free is a given.”
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.